Tư duy quan sát hệ thống (observability) – Kỹ năng ít được dạy nhưng rất cần có
Khi hệ thống gặp sự cố, việc khôi phục nhanh chóng không chỉ phụ thuộc vào khả năng phản ứng kỹ thuật, mà trước tiên là khả năng hiểu điều gì đang xảy ra, bắt đầu từ đâu, lan đến mức độ nào và vì sao lại phát sinh.
Observability – hay còn gọi là khả năng quan sát hệ thống – là kỹ năng then chốt để trả lời các câu hỏi đó. Không đơn thuần là sử dụng công cụ giám sát, observability là một tư duy thiết kế hệ thống sao cho có thể đo lường, giám sát và phân tích được hành vi nội tại từ bên ngoài. Đây là năng lực mà mọi kỹ sư DevOps hay Infra Engineer hiện đại đều cần trang bị, nhưng rất ít nơi dạy một cách có hệ thống.
Quan sát không phải chỉ để biết có sự cố
Phần lớn hệ thống đều có mức độ “monitoring” nhất định – chẳng hạn như thiết lập cảnh báo khi CPU vượt ngưỡng, hoặc theo dõi số lượng lỗi trả về từ API. Nhưng điều đó chưa đủ.
Monitoring chỉ cho biết khi nào có vấn đề. Còn observability giúp kỹ sư trả lời tiếp: vấn đề đó là gì, ảnh hưởng đến đâu, liên quan đến thành phần nào, có lặp lại hay không, và nguyên nhân sâu xa là gì.
Trong các hệ thống phức tạp – đặc biệt là microservices – một lỗi đơn giản có thể phát sinh từ một chuỗi nguyên nhân liên kết. Không có khả năng quan sát tốt, việc phân tích sự cố sẽ phụ thuộc hoàn toàn vào cảm tính và kinh nghiệm cá nhân.
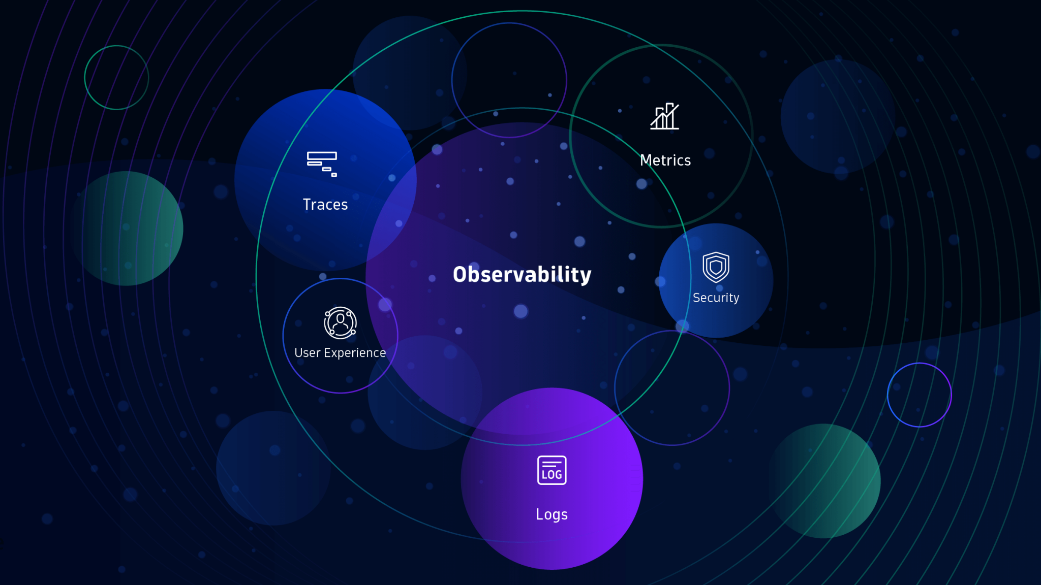
Ba trụ cột chính: Logs, Metrics, Traces
Một hệ thống có khả năng quan sát đầy đủ thường dựa trên ba loại tín hiệu: log, metric và trace.
Log phản ánh sự kiện cụ thể xảy ra trong hệ thống: người dùng thực hiện thao tác gì, hệ thống trả lỗi nào, dịch vụ nào gặp vấn đề. Khi được cấu trúc hợp lý, log sẽ cho phép truy vết theo request hoặc user cụ thể.
Metric là các chỉ số định lượng, như thời gian phản hồi trung bình, tỉ lệ lỗi theo phút, hoặc mức sử dụng tài nguyên. Chúng giúp theo dõi xu hướng, phát hiện bất thường và thiết lập cảnh báo chủ động.
Trace ghi nhận toàn bộ hành trình của một request khi đi qua các thành phần khác nhau trong hệ thống. Nó cực kỳ hữu ích để xác định điểm nghẽn, chẩn đoán chậm trễ và phân tích hiệu suất trong môi trường phân tán.
Thay vì dùng ba loại dữ liệu một cách rời rạc, các hệ thống hiện đại có xu hướng liên kết log, metric và trace theo một request ID duy nhất, tạo thành cái nhìn toàn diện và có ngữ cảnh.
Không thể "gắn thêm" observability sau khi hệ thống đã chạy
Nhiều người xem việc quan sát là phần việc “sau khi xong code”. Đây là một hiểu lầm phổ biến. Một hệ thống tốt về mặt observability cần được thiết kế từ đầu để phát tín hiệu đúng cách.
Điều đó bao gồm việc:
-
Chuẩn hóa định dạng log để dễ phân tích
-
Gắn mã định danh cho mọi luồng xử lý
-
Xây dựng dashboard và alert có ngữ cảnh, bám sát mục tiêu vận hành
-
Đảm bảo trace có mặt đầy đủ trong các thành phần giao tiếp quan trọng
Khi hệ thống “mù mờ”, dù có chạy đúng chức năng, cũng sẽ gây khó khăn lớn cho việc khắc phục lỗi, tối ưu hiệu suất hoặc đảm bảo SLA.
Công cụ hỗ trợ chỉ là phần ngọn
Trên thực tế, có rất nhiều nền tảng hỗ trợ triển khai observability: AWS CloudWatch, OpenTelemetry, Grafana, Prometheus, Datadog, New Relic, v.v. Tuy nhiên, việc lựa chọn công cụ chỉ mang lại hiệu quả nếu đi kèm với tư duy thiết kế hệ thống quan sát được.
Bạn có thể có hàng trăm dashboard, nhưng nếu log không có trace ID, hoặc metric không gắn nhãn theo người dùng hay dịch vụ, thì khi có sự cố, vẫn phải dò từng dòng log thủ công để tìm dấu hiệu bất thường.
Observability và khả năng phục hồi vận hành
Một hệ thống không tránh khỏi sự cố. Khác biệt nằm ở khả năng phát hiện nhanh, xác định đúng nguyên nhân và phục hồi hiệu quả. Observability không chỉ giúp giảm thời gian khắc phục (MTTR), mà còn tăng khả năng phối hợp giữa đội vận hành và đội phát triển, giảm xung đột và cải thiện chất lượng sản phẩm dài hạn.
Trong các tổ chức lớn, tư duy observability còn là nền tảng để triển khai AIOps – tự động hóa phản ứng với sự cố dựa trên dữ liệu quan sát được.
Kết luận
Observability không phải là một bộ công cụ, cũng không phải là bước thêm vào sau khi xây dựng hệ thống. Đó là một tư duy kỹ thuật cần có từ sớm, đặc biệt trong các môi trường phức tạp và đòi hỏi độ tin cậy cao.
Kỹ sư hiện đại không chỉ viết code và triển khai, mà còn cần biết nhìn vào hệ thống qua dữ liệu – để hiểu, chẩn đoán và phản ứng với những gì đang diễn ra. Đây là kỹ năng không thể thiếu nếu bạn muốn tiến xa trong vai trò DevOps hoặc vận hành hạ tầng.