Tại sao sinh viên nên học SQL thành thạo trước khi học Spark hay Kafka?
Trong thời đại Big Data và các hệ thống phân tán trở thành tiêu chuẩn trong xử lý dữ liệu, các công nghệ như Apache Spark và Apache Kafka nhanh chóng trở thành những công cụ chủ chốt mà nhiều sinh viên và kỹ sư dữ liệu trẻ muốn nắm bắt. Tuy nhiên, trong quá trình học và triển khai các hệ thống hiện đại này, nhiều người bỏ qua một nền tảng cực kỳ quan trọng – đó là SQL.
Không ít sinh viên tìm đến Spark hoặc Kafka với kỳ vọng rằng đây là những “con đường tắt” để tiếp cận công nghệ dữ liệu tiên tiến. Nhưng chính điều này lại khiến họ gặp trở ngại: không hiểu bản chất của truy vấn dữ liệu, không nắm rõ cách dữ liệu được phân tích, nhóm, lọc hoặc biến đổi. Từ đó, họ khó có thể khai thác được toàn bộ sức mạnh của các công cụ hiện đại. Vì vậy, học SQL trước khi tiếp cận các nền tảng phức tạp hơn như Spark hay Kafka không chỉ là một lựa chọn thông minh mà còn là một bước đi chiến lược.
SQL – Ngôn ngữ gốc của dữ liệu
SQL ra đời từ những năm 1970 và đến nay vẫn là ngôn ngữ tiêu chuẩn để tương tác với các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) như MySQL, PostgreSQL, SQL Server, Oracle… Không chỉ dừng lại ở đó, SQL còn được tích hợp và hỗ trợ trong rất nhiều hệ thống hiện đại – bao gồm cả Spark SQL hay các nền tảng như BigQuery, Athena, Presto, Trino.

SQL không phải là một công cụ “cũ kỹ”, mà là một nền tảng tư duy dữ liệu. Nó giúp bạn hiểu:
-
Dữ liệu được lưu trữ như thế nào trong các bảng.
-
Làm thế nào để chọn lọc dữ liệu bằng các điều kiện (WHERE).
-
Cách nhóm dữ liệu (GROUP BY), tính tổng hợp (SUM, COUNT, AVG…).
-
Cách kết hợp dữ liệu từ nhiều bảng khác nhau (JOIN).
-
Tư duy pipeline trong truy vấn: từ lọc đến nhóm, rồi đến phân tích nâng cao.
Khi đã vững SQL, bạn sẽ hiểu rõ hơn những gì đang diễn ra dưới lớp “vỏ” của các công cụ như Spark hay Kafka Streams. Bạn không chỉ viết được code, mà còn hiểu tại sao nên viết như vậy, và liệu cách làm đó có hiệu quả hay không.
Spark và Kafka – Mạnh mẽ nhưng không thay thế SQL
Apache Spark là một nền tảng xử lý dữ liệu phân tán rất mạnh, có khả năng xử lý hàng terabyte dữ liệu một cách song song. Apache Kafka là hệ thống hàng đầu để truyền tải dữ liệu theo thời gian thực, đóng vai trò như “dòng máu” trong các hệ thống streaming. Cả hai đều hỗ trợ xử lý dữ liệu ở quy mô lớn, tốc độ cao.
Nhưng điều mà nhiều sinh viên không để ý là: Spark và Kafka không thay thế SQL, mà còn phụ thuộc vào SQL rất nhiều.
-
Spark SQL là một thành phần cốt lõi trong Spark, cho phép bạn viết truy vấn SQL thay vì phải viết code Scala hay Python phức tạp.
-
DataFrame API của Spark gần như là “phiên bản lập trình” của SQL – các thao tác như filter(), groupBy(), select() đều tương đương với các câu lệnh SQL cơ bản.
-
Kafka Streams hay ksqlDB (một nền tảng mở rộng của Kafka) cho phép bạn thao tác dữ liệu streaming bằng cú pháp SQL chuẩn, áp dụng trên các luồng dữ liệu động.
Nếu bạn không hiểu SQL, bạn sẽ dễ viết những đoạn code Spark DataFrame khó đọc, khó tối ưu. Bạn có thể xử lý được dữ liệu, nhưng không khai thác được tối đa sức mạnh của Spark. Ngược lại, nếu đã quen với SQL, việc chuyển sang viết DataFrame hoặc sử dụng Spark SQL sẽ trở nên tự nhiên, mạch lạc và hiệu quả hơn nhiều.
Tư duy dữ liệu bắt đầu từ SQL
Một điều ít ai nói rõ, nhưng rất quan trọng: học SQL không chỉ là học cú pháp, mà là học tư duy dữ liệu.
Khi bạn viết một câu lệnh SQL, bạn đang mô tả cách bạn muốn nhìn dữ liệu, không phải cách để “lập trình” dữ liệu. SQL là một ngôn ngữ khai báo – bạn mô tả cái bạn muốn, chứ không phải cách để làm ra nó từng bước một.

Chính điều này tạo ra một nền tảng rất tốt cho sinh viên muốn làm việc với dữ liệu. Vì khi chuyển sang học Spark, Kafka hay các hệ thống lớn hơn, bạn sẽ gặp rất nhiều khái niệm trừu tượng:
-
Logical Plan, Physical Plan trong Spark.
-
Topic, Partition, Consumer Group trong Kafka.
-
Watermark, Windowing trong stream processing.
Nếu chưa có tư duy tổ chức dữ liệu vững vàng, bạn dễ cảm thấy mọi thứ rối rắm, mơ hồ. Nhưng nếu bạn đã quen với cách nghĩ có hệ thống từ SQL – từ SELECT, WHERE, JOIN, GROUP BY – thì bạn sẽ dễ dàng liên kết chúng với các thao tác tương tự trong Spark/Kafka, chỉ khác về ngữ cảnh hoặc cú pháp.
Những sai lầm phổ biến khi bỏ qua SQL
Trong quá trình hướng dẫn sinh viên và kỹ sư dữ liệu trẻ, chúng tôi nhận thấy một số sai lầm thường gặp:
-
Học Spark/Kafka bằng cách sao chép code mẫu, không hiểu bản chất truy vấn.
-
Viết DataFrame hoặc thao tác stream một cách “cơ học”, dẫn đến hiệu suất thấp.
-
Không thể debug lỗi logic trong pipeline dữ liệu, vì không hiểu từng bước dữ liệu được biến đổi thế nào.
-
Dễ bị phụ thuộc vào framework, mất khả năng tư duy độc lập.
Tất cả những điều này đều bắt nguồn từ việc thiếu nền tảng SQL. S
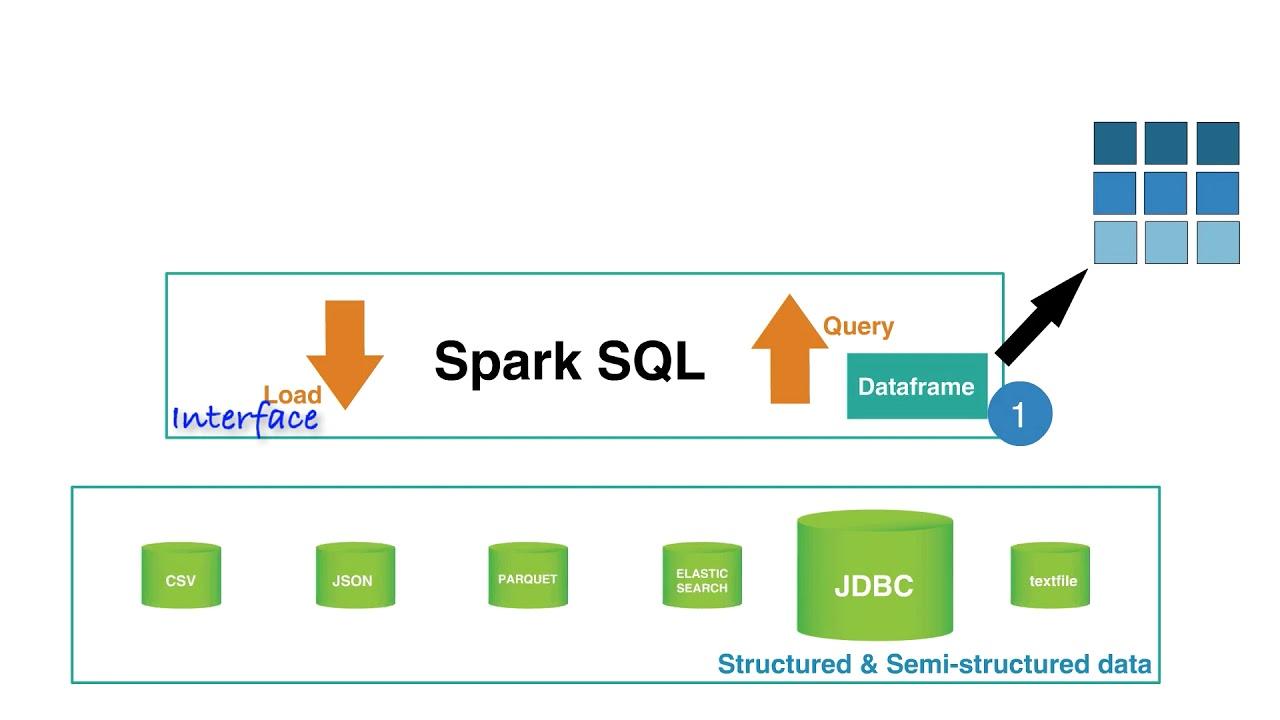
SQL vẫn luôn là điểm khởi đầu đúng đắn
Bạn không cần phải thành chuyên gia SQL mới có thể học Spark hay Kafka. Nhưng một sự thành thạo vừa đủ – hiểu rõ cách viết truy vấn, biết cách tổ chức dữ liệu theo chiều dọc (record) và chiều ngang (schema), biết kết hợp, tổng hợp, lọc, nhóm – sẽ tạo cho bạn một bệ phóng cực kỳ vững chắc.
Từ đó, việc học các công cụ như Spark SQL, PySpark, ksqlDB hay Flink SQL sẽ trở nên dễ dàng hơn nhiều. Bạn không chỉ học để sử dụng được, mà còn học để làm chủ những công nghệ đó.
Kết luận
SQL là ngôn ngữ nền tảng cho mọi thao tác dữ liệu – từ những bảng đơn giản trong MySQL cho đến các pipeline streaming phức tạp chạy trên Spark hoặc Kafka. Với sinh viên hoặc bất kỳ ai mới bắt đầu con đường trở thành kỹ sư dữ liệu hoặc nhà phân tích, việc học và thành thạo SQL không chỉ là một gợi ý, mà là một bước đi bắt buộc nếu bạn muốn đi xa.
Đừng vội vàng lao vào những công nghệ mới mẻ mà bỏ qua nền tảng. Học SQL trước – bạn sẽ thấy những công cụ mạnh mẽ như Spark hay Kafka thực ra rất logic, rất gần gũi, và cực kỳ thú vị.