Tại sao 80% thời gian làm AI là để làm sạch dữ liệu? – Câu chuyện thật từ công ty lớn
Trong suy nghĩ của nhiều sinh viên và người mới học trí tuệ nhân tạo (AI), phần hấp dẫn nhất luôn là việc xây dựng model: chọn thuật toán, tối ưu loss, chạy thử, rồi khoe kết quả accuracy cao ngất. Nhưng thực tế ở các công ty lớn như Google, Amazon, Grab lại hoàn toàn khác: hầu hết thời gian của các team AI được dành để… làm sạch dữ liệu.
Một báo cáo nổi tiếng của IBM từng nói: "Data scientists spend 80% of their time cleaning and organizing data, and only 20% analyzing it." Và theo chia sẻ từ các kỹ sư AI thực chiến tại các tập đoàn, con số 80% này không hề nói quá.
Vậy vì sao việc "làm sạch dữ liệu" lại chiếm nhiều thời gian đến vậy? Có phải do kỹ năng yếu hay quy trình kém? Hay đó là bản chất thật sự của việc triển khai AI trong môi trường thực tế?

Câu chuyện từ các công ty lớn: Model không phải là vấn đề
Tại hội thảo AWS re:Invent, một kỹ sư của Amazon Machine Learning từng chia sẻ:
“AI projects fail not because of weak models, but due to bad or incomplete data.”
Tương tự, tại Grab, các kỹ sư AI chịu trách nhiệm dự đoán nhu cầu đặt xe phải đối mặt với hàng trăm vấn đề:
-
Dữ liệu vị trí bị mất GPS, sai timestamp.
-
Thông tin đơn hàng thiếu trường bắt buộc.
-
Dữ liệu người dùng bị nhân đôi hoặc trùng lặp.
-
Các khu vực địa lý không được chuẩn hóa dẫn đến kết quả sai lệch.
Một kỹ sư của Google Brain, Andrew Ng, từng nói:
“ In AI, data is food. Bad data, bad results. Cleaning up data is often more valuable than tuning a model”
Tất cả các câu chuyện đều dẫn đến một kết luận chung: Dữ liệu là yếu tố sống còn của AI, và việc xử lý dữ liệu chiếm phần lớn công sức của đội ngũ kỹ thuật.
Vì sao việc "data cleaning" lại tốn nhiều công sức đến vậy?
Vậy cụ thể, “data cleaning” bao gồm những công việc gì mà lại tiêu tốn đến 80% thời gian của một dự án AI? Thực tế, quá trình này không chỉ đơn thuần là xóa dòng trống hay sửa lỗi chính tả trong dữ liệu. Nó là một chuỗi các bước kỹ thuật – từ loại bỏ giá trị trùng lặp, xử lý dữ liệu thiếu, đến chuẩn hóa đầu ra và phát hiện ngoại lệ.
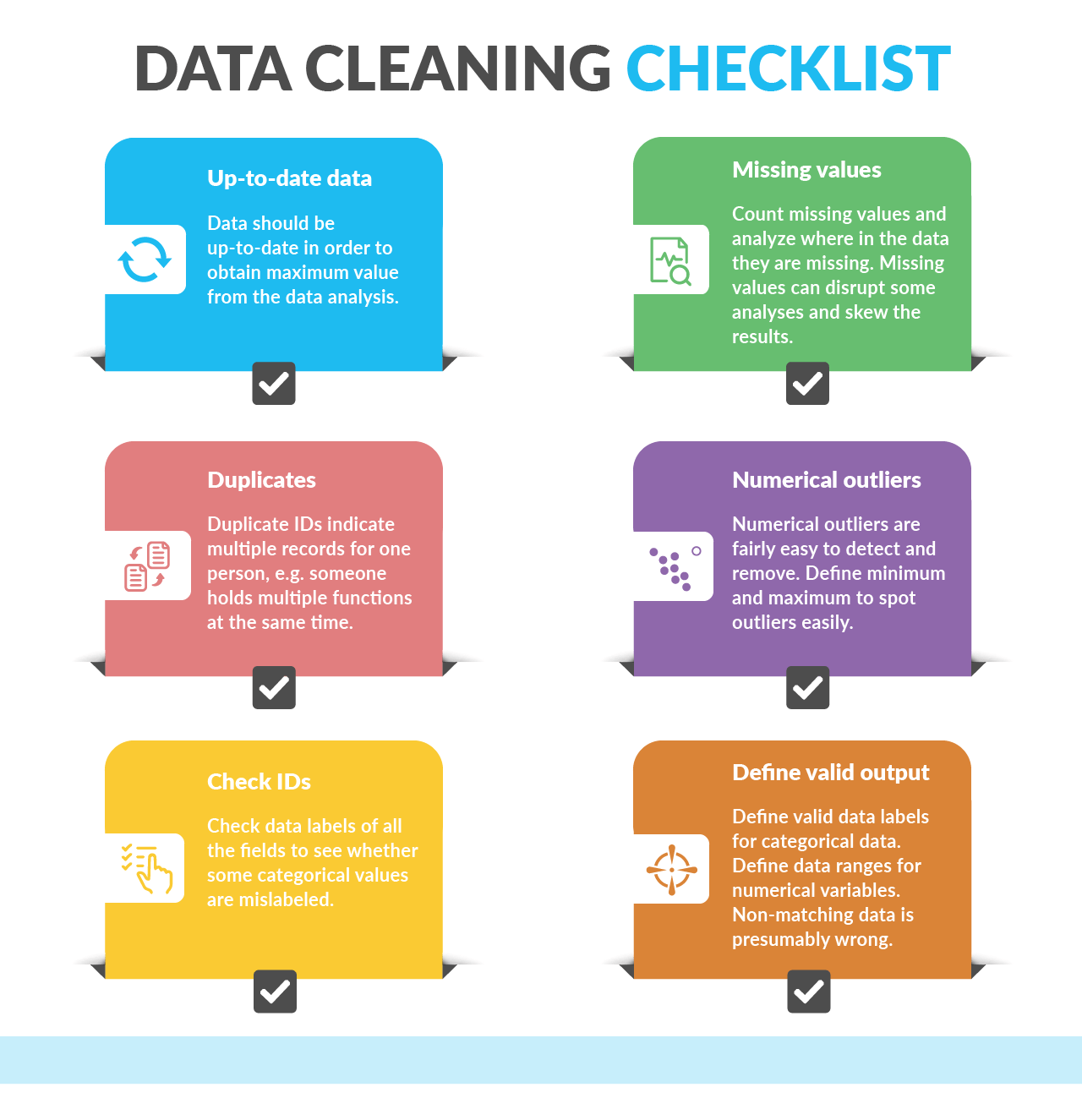
1. Dữ liệu thực tế luôn bẩn, thiếu, lệch chuẩn
Trong thế giới học thuật, bạn thường làm việc với các bộ dữ liệu đẹp như Titanic, MNIST, Iris… – dữ liệu đã được xử lý, định dạng chuẩn, sạch sẽ như trong phòng thí nghiệm.
Nhưng trong thực tế:
-
Nhiều trường bị thiếu ().
-
Dữ liệu định dạng không đồng nhất: ngày tháng, số lượng, ký hiệu khác nhau giữa hệ thống.
-
Trường văn bản (text) bị lỗi mã hóa, dính tag HTML, chứa từ viết tắt, emoji…
-
Có hàng loạt giá trị sai logic: tuổi = -5, giá = 0, khách hàng đã nghỉ vẫn còn giao dịch.
→ Tất cả đều cần được phát hiện, sửa chữa, và xử lý hợp lý trước khi dùng để huấn luyện AI.

2. Dữ liệu đến từ nhiều nguồn khác nhau
Một hệ thống AI có thể lấy dữ liệu từ:
-
Database giao dịch (MySQL, PostgreSQL…)
-
Log file (JSON, CSV…)
-
API của đối tác
-
Sensor hoặc thiết bị IoT
-
Dữ liệu người dùng nhập vào thủ công
→ Mỗi nguồn sẽ có định dạng, lỗi và mức độ đáng tin cậy khác nhau. Gộp chúng lại thành một dataset huấn luyện yêu cầu công sức rất lớn.

3. Dữ liệu thay đổi liên tục (data drift)
Một mô hình AI không phải train một lần rồi dùng mãi. Dữ liệu đầu vào thay đổi mỗi ngày:
-
Người dùng có hành vi mới.
-
Chính sách, giá sản phẩm, khu vực vận hành thay đổi.
-
Định nghĩa nghiệp vụ (business logic) được cập nhật.
→ Cần liên tục theo dõi, phát hiện "data drift" (dữ liệu lệch) và cập nhật lại dữ liệu huấn luyện.
4. Cần hiểu nghiệp vụ để xử lý đúng
Không thể làm sạch dữ liệu mà không hiểu bối cảnh nghiệp vụ:
-
Một giao dịch “hủy giữa chừng” là lỗi hệ thống hay hành vi bình thường?
-
Số lượng = 0 có phải là đơn hàng lỗi hay là “đơn hàng miễn phí”?
-
Dữ liệu thiếu ngày 29/2 có nên coi là hợp lệ?
→ Việc làm sạch dữ liệu đòi hỏi kỹ năng phân tích, tư duy logic, và hiểu biết nghiệp vụ sâu sắc.
Làm sao để sinh viên rèn luyện kỹ năng xử lý dữ liệu?
Dưới đây là một số hướng gợi ý để bạn phát triển kỹ năng data cleaning – yếu tố quyết định thành bại của một dự án AI:
1. Làm việc với dữ liệu thực tế, không phải dữ liệu demo
Thay vì làm Titanic hay Iris, hãy:
-
Tải log dữ liệu từ Kaggle, data.gov.vn, hoặc data scraping từ web.
-
Làm mini project xử lý dữ liệu từ nhiều nguồn: Google Sheets, API, file Excel lộn xộn.
-
Dùng công cụ như Pandas, SQL, Spark để xử lý dữ liệu bị thiếu, lỗi format, sai định dạng.
2. Học cách phân tích dữ liệu trước khi modeling
Trước khi đưa dữ liệu vào model:
-
Làm EDA (exploratory data analysis) kỹ lưỡng.
-
Kiểm tra phân phối, phát hiện outlier.
-
Nhìn dữ liệu bằng trực quan (charts, histogram, scatter plot).
-
Viết hàm kiểm tra tính nhất quán (consistency check).
3. Tìm hiểu các thư viện chuyên xử lý dữ liệu
-
Pandas (Python): thao tác dữ liệu bảng mạnh mẽ.
-
Great Expectations: kiểm tra chất lượng dữ liệu tự động.
-
dbt: chuẩn hóa và kiểm soát luồng dữ liệu trong hệ thống hiện đại.
-
PySpark: xử lý dữ liệu lớn trên cụm phân tán.
4. Học tư duy phân tầng xử lý dữ liệu
Dữ liệu không nên xử lý một lần duy nhất. Hãy tư duy theo tầng:
-
Raw data → cleaned data → structured data → modeling dataset
-
Mỗi tầng có logging, kiểm tra, lưu trữ riêng biệt.
→ Đây chính là kiến trúc dữ liệu hiện đại mà các công ty lớn như Airbnb, Netflix sử dụng.
5. Thực hành data validation liên tục
-
Định nghĩa rõ schema dữ liệu.
-
Đặt “expectation” cho từng cột: kiểu dữ liệu, min/max, không được null…
-
Viết unit test cho pipeline xử lý dữ liệu như test cho code.
Kết luận
AI không phải là cuộc chơi của những thuật toán "kỳ diệu", mà là cuộc chơi của sự kiên nhẫn, kỹ năng kỹ thuật và khả năng hiểu biết dữ liệu. Và phần lớn thời gian đó – lên đến 80% – là để làm những việc không hào nhoáng: làm sạch, xử lý, chuẩn hóa và hiểu dữ liệu.
Nếu bạn là sinh viên đang theo đuổi lĩnh vực AI hoặc Data Science, hãy bắt đầu từ:
-
Làm nhiều bài tập liên quan đến data cleaning.
-
Chủ động làm việc với dữ liệu thật và phức tạp.
-
Học cách viết pipeline dữ liệu có kiểm soát, có kiểm thử.
-
Và luôn tự hỏi: “Dữ liệu này đã sẵn sàng để train model chưa?”
Vì nếu không có dữ liệu tốt – mọi model dù mạnh cỡ nào cũng chỉ là rác.