Luồng dữ liệu không bao giờ ngủ: Apache Kafka hoạt động như thế nào?
Trong thời đại số hóa, dữ liệu được tạo ra liên tục, từ các giao dịch trực tuyến, cảm biến IoT, đến hoạt động người dùng trên mạng xã hội. Để xử lý những dòng dữ liệu “không bao giờ ngủ” này một cách hiệu quả, Apache Kafka đã trở thành công cụ hàng đầu cho việc quản lý dữ liệu streaming theo thời gian thực. Với khả năng thu thập, lưu trữ và phân phối dữ liệu 24/7, Kafka giúp các doanh nghiệp biến những dòng dữ liệu khổng lồ thành thông tin có giá trị. Hãy cùng khám phá cách Kafka hoạt động và tại sao nó là “trái tim” của các hệ thống dữ liệu hiện đại.
Apache Kafka là gì?
Apache Kafka là một nền tảng phân tán (distributed platform) được thiết kế để xử lý các luồng dữ liệu thời gian thực (real-time data streaming). Nó hoạt động như một hệ thống nhắn tin (messaging system) tốc độ cao, cho phép thu thập, lưu trữ và phân phối dữ liệu với độ trễ thấp và khả năng mở rộng vượt trội. Được phát triển bởi LinkedIn và sau đó trở thành một dự án mã nguồn mở, Kafka hiện là lựa chọn hàng đầu của các gã khổng lồ công nghệ như Netflix, Uber, và Spotify để xử lý hàng tỷ sự kiện mỗi ngày.

Kafka nổi bật với ba khả năng chính:
-
Thu thập dữ liệu: Tiếp nhận dữ liệu từ nhiều nguồn khác nhau, từ ứng dụng, cơ sở dữ liệu, đến thiết bị IoT.
-
Lưu trữ dữ liệu: Lưu trữ dữ liệu một cách đáng tin cậy trong thời gian dài hoặc ngắn, tùy thuộc vào nhu cầu.
-
Phân phối dữ liệu: Chuyển dữ liệu đến các hệ thống đích để xử lý, phân tích hoặc lưu trữ.
Kafka hoạt động như thế nào?
Để hiểu cách Kafka xử lý luồng dữ liệu liên tục, hãy cùng phân tích các thành phần cốt lõi và quy trình hoạt động của nó.
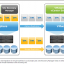
1. Các thành phần chính của Kafka
Kafka được xây dựng dựa trên một kiến trúc phân tán, bao gồm các thành phần sau:
-
Producer: Các ứng dụng hoặc hệ thống gửi dữ liệu (messages) đến Kafka. Ví dụ: Một ứng dụng thương mại điện tử gửi dữ liệu về mỗi lần người dùng nhấp chuột hoặc mua hàng.
-
Consumer: Các ứng dụng hoặc hệ thống nhận dữ liệu từ Kafka để xử lý hoặc phân tích. Ví dụ: Một hệ thống phân tích có thể đọc dữ liệu từ Kafka để tạo báo cáo thời gian thực.
-
Topic: Dữ liệu được tổ chức thành các “chủ đề” (topics), tương tự như các kênh dữ liệu. Mỗi topic là một danh mục mà producer gửi dữ liệu vào và consumer đọc dữ liệu từ đó.
-
Broker: Các máy chủ Kafka (Kafka brokers) chịu trách nhiệm lưu trữ và quản lý dữ liệu. Một cụm Kafka (Kafka cluster) thường bao gồm nhiều broker để đảm bảo khả năng mở rộng và chịu lỗi.
-
Partition: Mỗi topic được chia thành nhiều phân vùng (partitions) để xử lý song song, tăng hiệu suất và khả năng mở rộng.
-
ZooKeeper: Một dịch vụ quản lý cấu hình và đồng bộ hóa, giúp điều phối hoạt động của các broker trong cụm Kafka.
2. Thu thập dữ liệu
Kafka hoạt động như một “đường cao tốc” cho dữ liệu. Các producer gửi dữ liệu đến các topic trong Kafka dưới dạng các bản tin (messages). Mỗi bản tin bao gồm:
-
Key: Một giá trị giúp xác định phân vùng mà bản tin sẽ được gửi đến.
-
Value: Dữ liệu thực tế (có thể là JSON, văn bản, hoặc bất kỳ định dạng nào).
-
Timestamp: Thời gian bản tin được tạo.
Ví dụ: Trong một ứng dụng thương mại điện tử, mỗi khi người dùng thêm sản phẩm vào giỏ hàng, một producer sẽ gửi một bản tin đến topic “cart_events” với thông tin về sản phẩm, người dùng, và thời gian.
Kafka cho phép thu thập dữ liệu từ hàng nghìn nguồn khác nhau, từ ứng dụng web, cảm biến IoT, đến nhật ký hệ thống (logs), mà không bị tắc nghẽn nhờ kiến trúc phân tán và khả năng xử lý song song.
3. Lưu trữ dữ liệu
Dữ liệu được gửi đến Kafka không chỉ được xử lý ngay lập tức mà còn có thể được lưu trữ để sử dụng sau này. Các bản tin trong một topic được lưu trữ trong các phân vùng (partitions), và mỗi phân vùng hoạt động như một nhật ký (log) có thứ tự. Kafka lưu trữ dữ liệu trên đĩa, nhưng được tối ưu hóa để truy cập nhanh nhờ cơ chế tuần tự (sequential I/O).
Điểm đặc biệt của Kafka là:
-
Thời gian lưu trữ linh hoạt: Bạn có thể cấu hình để lưu dữ liệu trong vài giờ, vài ngày, hoặc thậm chí vô thời hạn.
-
Khả năng chịu lỗi: Dữ liệu được sao chép (replicated) trên nhiều broker để đảm bảo không bị mất ngay cả khi một broker gặp sự cố.
Ví dụ: Một hệ thống giám sát IoT có thể lưu trữ dữ liệu cảm biến trong topic “sensor_data” trong 7 ngày để phân tích xu hướng, trong khi dữ liệu giao dịch tài chính có thể được lưu trữ vĩnh viễn.
4. Phân phối dữ liệu
Kafka hoạt động như một “người môi giới” trung gian, cho phép các consumer đọc dữ liệu từ các topic theo cách linh hoạt. Các consumer có thể:
-
Đọc dữ liệu theo thời gian thực để xử lý ngay lập tức.
-
Đọc lại dữ liệu cũ từ một thời điểm cụ thể (nhờ cơ chế lưu trữ nhật ký).
-
Thuộc các nhóm consumer (consumer groups) để phân phối tải xử lý trên nhiều ứng dụng.
Ví dụ: Trong một hệ thống thương mại điện tử, một consumer có thể đọc dữ liệu từ topic “order_events” để cập nhật kho hàng, trong khi một consumer khác đọc cùng topic để tạo báo cáo doanh thu thời gian thực.
Kafka hỗ trợ pub/sub model (publish/subscribe), trong đó nhiều consumer có thể đăng ký vào cùng một topic mà không ảnh hưởng đến nhau. Điều này giúp Kafka trở nên lý tưởng cho các ứng dụng cần xử lý dữ liệu đồng thời, như hệ thống đề xuất, phân tích thời gian thực, hoặc giám sát.
5. Khả năng mở rộng và chịu lỗi
Kafka được thiết kế để xử lý khối lượng dữ liệu khổng lồ với độ trễ thấp. Một số đặc điểm nổi bật:
-
Mở rộng ngang: Thêm broker vào cụm Kafka để tăng khả năng xử lý.
-
Song song hóa: Dữ liệu được chia thành các phân vùng để xử lý đồng thời.
-
Chịu lỗi: Dữ liệu được sao chép trên nhiều broker, đảm bảo hệ thống vẫn hoạt động ngay cả khi một số broker bị lỗi.
Lợi ích của Kafka trong xử lý dữ liệu streaming

Kafka mang lại những giá trị to lớn cho các tổ chức cần xử lý luồng dữ liệu liên tục:
-
Thời gian thực: Xử lý dữ liệu với độ trễ gần bằng 0, lý tưởng cho các ứng dụng như phát hiện gian lận hoặc giám sát hệ thống.
-
Khả năng mở rộng: Hỗ trợ hàng tỷ bản tin mỗi ngày mà không làm giảm hiệu suất.
-
Tính linh hoạt: Phù hợp với nhiều trường hợp sử dụng, từ phân tích dữ liệu, giám sát, đến tích hợp hệ thống.
-
Độ tin cậy: Đảm bảo dữ liệu không bị mất nhờ cơ chế sao chép và lưu trữ bền vững.
Ứng dụng thực tế của Kafka
Kafka được sử dụng rộng rãi trong nhiều ngành công nghiệp:
-
Thương mại điện tử: Theo dõi hành vi người dùng, quản lý đơn hàng, và tối ưu hóa kho hàng (như Amazon).
-
Tài chính: Phát hiện gian lận thời gian thực và xử lý giao dịch (như PayPal).
-
IoT: Thu thập và phân tích dữ liệu từ hàng triệu cảm biến (như trong các hệ thống thành phố thông minh).
-
Truyền thông: Gửi thông báo và đề xuất nội dung cá nhân hóa (như Netflix).
Kết luận: Kafka – Động cơ của luồng dữ liệu hiện đại
Apache Kafka không chỉ là một công cụ, mà là một hệ sinh thái mạnh mẽ giúp doanh nghiệp khai thác sức mạnh của dữ liệu streaming. Bằng cách thu thập, lưu trữ và phân phối dữ liệu một cách hiệu quả, Kafka đảm bảo rằng các luồng dữ liệu “không bao giờ ngủ” luôn được xử lý nhanh chóng và đáng tin cậy. Nếu bạn đang tìm cách xây dựng một hệ thống dữ liệu thời gian thực, Kafka chính là chìa khóa để biến dữ liệu thành giá trị thực tiễn.